
Three weeks before his Google loop, a data engineer I'll call Rohit did what everyone does: 200 LeetCode problems, half of them dynamic programming. Round two, the interviewer shared a table of streaming events and asked how he'd handle records that arrive four hours late. Rohit had spent twenty days preparing for red-black trees. Nobody at Google has asked anyone about red-black trees in a data engineering loop, possibly ever.
That's the core misunderstanding about Google data engineer interview questions: it's not a software engineer loop with a different job title. The rounds are built around SQL depth, practical Python, and — the part almost nobody rehearses — explaining pipeline tradeoffs out loud to another engineer. I built Greenroom after freezing in exactly that kind of spoken round, so this guide covers both the questions and the delivery.
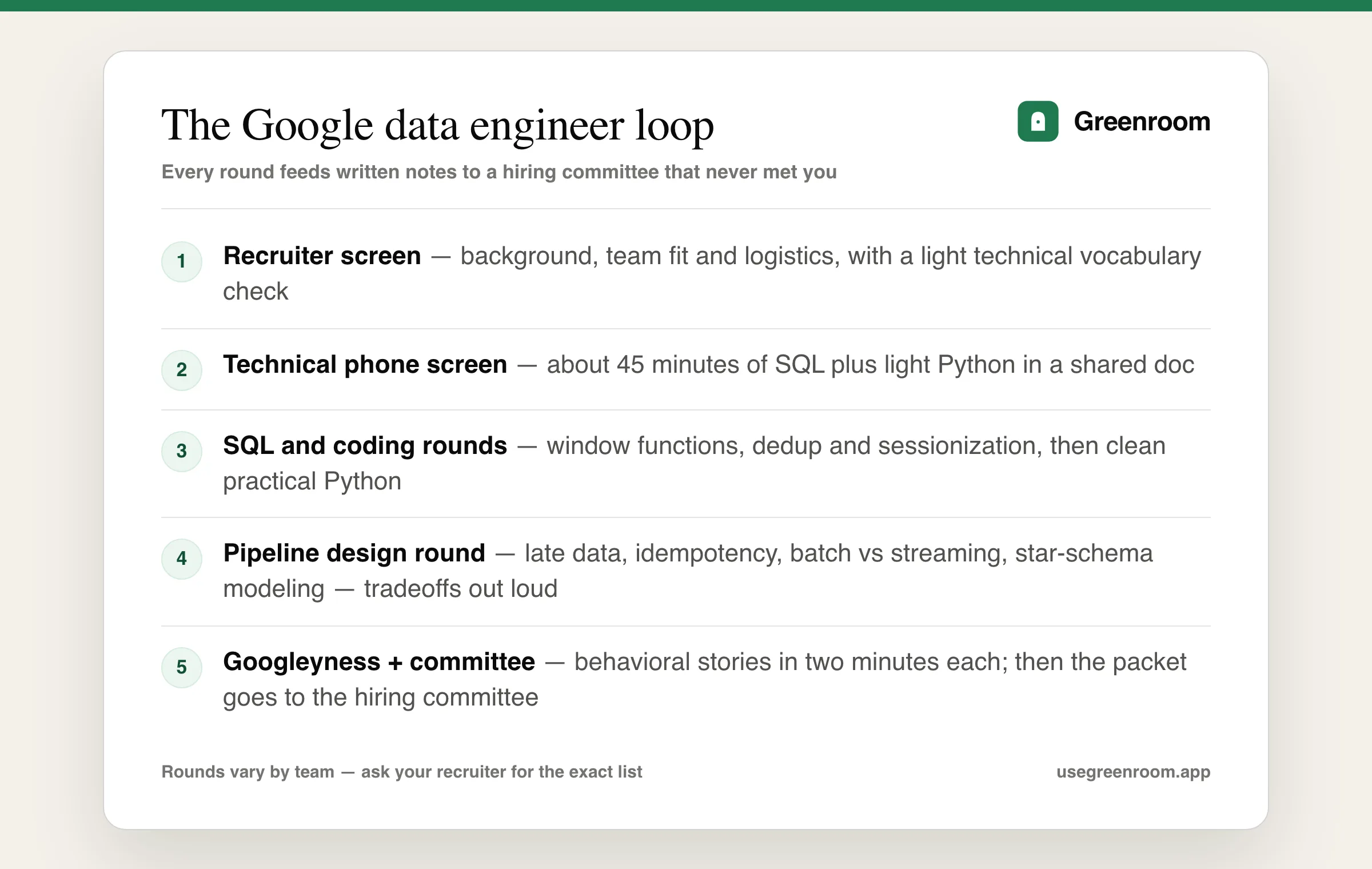
The Google data engineer interview process in 2026
Data engineer roles at Google sit in several orgs — Cloud, gTech, product analytics teams — so loops vary slightly, but candidates consistently report the same skeleton for the Google data engineer interview process:
- Recruiter screen — background, team fit, logistics; light technical vocabulary check.
- Technical phone screen — 45 minutes, usually SQL plus light Python in a shared doc.
- The loop — four to five rounds: SQL depth, Python coding, pipeline design and data modeling, and a behavioral round (the famous Googleyness check).
- Hiring committee — your packet is reviewed by people who never met you, which is why interviewers take detailed notes on how you reasoned, not just whether you finished.
That last point deserves a highlight: your spoken explanation literally becomes the written evidence. A correct query you can't explain scores worse than a near-correct one you narrated clearly. Ask your recruiter for the exact round list — they will tell you, and knowing it beats guessing.
Google data engineer SQL interview questions
SQL is the heart of the loop, and the bar is well past textbook joins. The recurring Google data engineer SQL questions cluster around window functions, deduplication and sessionization on realistic event data:
Keep only the latest record per user.
The single most common pattern. Know it cold, including why ROW_NUMBER and not RANK:
-- latest event per user from a duplicated event stream
SELECT user_id, event_type, event_time
FROM (
SELECT *,
ROW_NUMBER() OVER (
PARTITION BY user_id ORDER BY event_time DESC
) AS rn
FROM events
)
WHERE rn = 1;Then come the follow-ups, which are where the round is actually decided: what changes with duplicate timestamps, how RANK and DENSE_RANK differ, how NULLs behave in aggregates and joins, and how you'd make this cheaper on a table with billions of rows (partitioning, clustering, filtering early). Our SQL interview questions guide covers the full window-function family; drill it until the syntax is boring.
Sessionize a clickstream.
Given raw click events, group them into sessions separated by 30 minutes of inactivity — a LAG over event time, a gap flag, and a running sum. If you can talk through sessionization clearly, you're ahead of most of the loop.
Google data engineer coding interview questions
The coding rounds are Python-flavored and gentler than a software engineer loop — but "gentler" means easy-to-medium, not optional. Reported staples: parse a log file and aggregate by key, flatten nested records, top-N frequent items, and light string manipulation. Clean code plus narration wins:
from collections import Counter
def top_pages(log_lines, n=3):
"""Count page hits from 'user timestamp page' log lines."""
pages = (line.split()[2] for line in log_lines if line.strip())
return Counter(pages).most_common(n)Interviewers probe edge cases — malformed lines, memory limits if the file doesn't fit in RAM (stream it, don't read it) — and expect you to mention them before being asked. The Python interview questions guide covers the language layer underneath.
Pipeline design and data modeling questions at Google
This is the round Rohit met his late-arriving events in, and it has no single right answer by design. Recurring prompts: design a daily pipeline for product analytics, handle late and duplicate data, backfill a broken week, choose batch versus streaming, and model a star schema for a reporting use case. What's scored is the tradeoff reasoning:
- Late data — watermarks or a reprocessing window; say how late is acceptable and what happens after the cutoff.
- Idempotency — reruns must not double-count; partition-overwrite beats append for recovery.
- Batch vs streaming — name the freshness requirement first; streaming is a cost you pay for a reason, not a default.
- Modeling — facts and dimensions, grain first, and when you'd denormalize for query cost.
Our data engineer interview questions guide goes deeper on ETL-vs-ELT, warehousing and Spark; the Google data engineer prep page has a compact round-by-round checklist for this exact role.
Googleyness and the behavioral round
Google's behavioral round looks for collaboration, intellectual honesty and comfort with ambiguity — "Googleyness." The questions are standard (a conflict, a failure, a time you changed your mind with data); the bar is specificity. One real project story told with numbers beats five rehearsed adjectives. And because the packet goes to a committee, rambling is expensive: practice landing each story in about two minutes, out loud, with a structure the note-taker can actually capture.
LeetCode, StrataScratch, DataLemur — where each actually fits
An honest map of the prep stack, because they solve different problems:
- LeetCode — right for the Python rounds at easy-to-medium level; wrong as the main event. The DE loop is not an algorithms contest, and DP grinding is misallocated hours here.
- StrataScratch and DataLemur — the best drills for interview-style SQL on realistic product data; DataLemur's free tier is genuinely good for window functions. Their limit: typing a correct query in silence is half the round. The other half is defending it through follow-ups.
- GeeksforGeeks interview experiences — useful for calibrating what past candidates faced; quality varies, treat them as anecdotes, not a syllabus.
- ChatGPT — fine for generating practice prompts and reviewing written answers; it won't interrupt you mid-answer the way a Google interviewer will.
- Greenroom — the spoken layer. Ari, the AI interviewer, runs the round out loud, pushes follow-ups when your pipeline answer hand-waves, and scores clarity and structure — the thing the hiring committee actually reads. Fair tradeoff: Ari won't teach you window functions; pair it with the SQL drills above.
How to prepare for the Google data engineer interview
- Weeks 1–2: SQL depth — window functions, dedup, sessionization, NULL behavior — drilled daily until fluent, then explained out loud to a wall, a friend, or Ari.
- Week 3: Python — log parsing, transforms, generators for streaming; one timed easy-medium problem a day with full narration.
- Week 4: pipeline design — pick three prompts (daily analytics pipeline, backfill plan, batch-to-streaming migration) and answer each aloud in 20 minutes, twice.
- Final week: two full spoken mocks plus your behavioral stories timed at two minutes each. Then read the role-specific prep page the night before, not a new textbook.
If Meta is also on your list, the loops rhyme but weight differently — our Meta data engineer interview questions guide covers the SQL-heavier, product-sense-flavored version, and the complete Google preparation guide covers the general SWE process if you're deciding between tracks.
Frequently asked questions
What is the Google data engineer interview process?
Candidates consistently report: a recruiter screen, a technical phone screen mixing SQL and light coding, then a loop of four to five rounds covering SQL depth, Python coding, pipeline design and data modeling, and a behavioral (Googleyness) round. Feedback then goes through Google's hiring-committee review rather than being decided by one interviewer.
How many rounds are there in the Google data engineer interview?
Typically five to six conversations end to end: one recruiter screen, one technical phone screen, and a loop of four to five interviews. Exact shape varies by team — data engineer roles sit in Cloud, gTech and product teams, and each tunes the loop slightly, so ask your recruiter for the exact round list. They will tell you.
Is the Google data engineer interview hard?
It is deep rather than tricky. The SQL goes well past textbook joins into window functions and edge cases, the coding is easier than a software engineer loop but must be clean, and the pipeline-design round has no single right answer — it scores how you reason about tradeoffs out loud. Most rejections come from unclear explanations, not missing knowledge.
What SQL questions does Google ask data engineers?
Expect window functions (ROW_NUMBER, RANK, LAG), deduplicating event data, sessionization, joins with NULL traps, and aggregation questions framed on realistic product data. Interviewers push follow-ups — how the query behaves with late or duplicate events, and how you would make it cheaper on very large tables.
Does the Google data engineer interview include coding?
Yes, usually in Python. It is lighter than a software engineer loop — parsing logs, transforming records, dictionary and string manipulation, occasionally an easy-to-medium algorithm — but you are expected to write clean, working code and narrate your reasoning while you do it.
How long does the Google data engineer interview process take?
Plan for four to eight weeks from recruiter screen to decision in most reported cases: scheduling the loop takes time, and after the final round your packet goes to a hiring committee and then team matching. Use the gap between screen and loop as structured prep time rather than a waiting room.