
You finish a mock interview at 11:47pm, heart still doing the thing it does after talking out loud to a screen for thirty-five minutes, and a number appears: 6/10. You stare at it the way you'd stare at a text message that just says "we need to talk." Is 6 good? Is 6 the AI being polite? Is 6 the AI quietly judging the way you said "synergy" twice? You did not consent to being judged by a robot at midnight, and yet here you are, refreshing the page like the number might change if you look disappointed enough.
This is the moment this post exists for. An AI interview feedback report is only useful if you trust the number enough to act on it — and you can't trust a number you don't understand. So this is the actual mechanics: what's inside Greenroom's report, how the 1-10 interview scoring is built, which dimensions get graded, a real worked example showing a 4/10 answer turning into an 8/10 answer for the same question, and — because credibility matters more than hype — an honest list of what AI feedback genuinely cannot do for you. No "9/10, amazing!" marketing fluff here. Just the rubric, in daylight.
Worth saying up front, because it sets the tone for everything below: the goal of this post is not to convince you the score is magic. It's to convince you the score is legible — that every number traces back to something specific you can check, agree with, or push back on, the same way you'd want any grade that affects how you spend your prep time to be checkable rather than just trusted on faith.
The scene: staring at a number you don't trust
Let's set this up properly, because the panic is universal. You've just done a 30-minute spoken mock interview. Ari — Greenroom's AI interviewer — asked you to walk through a project, then followed up twice on a detail you mentioned in passing, then asked a behavioral question you weren't expecting, then thanked you and ended the call like nothing weird just happened. Thirty seconds later, a report loads: an overall score, a few category bars, and a paragraph of feedback that reads like it actually listened.
Your first instinct, if you're like most people, is to treat the number the way you'd treat a fortune cookie — interesting, vaguely ominous, not really actionable. Your second instinct, if the number is low, is to assume the AI "didn't get" what you meant. Your third instinct, if the number is suspiciously high, is to assume the AI is just being nice, the way ChatGPT tells you your terrible business plan has "real potential."
Both instincts are reasonable, because most of us have zero mental model for how an algorithm could possibly grade something as messy as human speech. So before defending or dismissing the number, it helps to actually open the hood. That's the whole point of this post: not "trust the AI," but "here is exactly what it measured, so you can decide for yourself whether the score is fair — and then use it to actually get better."
What's actually inside the report
Greenroom's feedback report isn't one number floating in a void. It's a structured breakdown with five layers, and each layer answers a different question about your answer.
1. The overall score (1-10). This is the headline number, and it's a weighted roll-up of the dimension scores below — not a separate "vibe check" the model does on its own. If you ever see an 8/10 overall, it's because the dimensions underneath it earned that average, not because the model "felt good" about your energy.
2. Per-dimension scores. Greenroom scores five core dimensions on every substantive answer: technical correctness, communication clarity, structure (STAR/BLUF adherence for behavioral and situational questions), depth on follow-ups, and confidence signals (including filler-word density). Each gets its own 1-10 score, visible in the report, not buried in a black box.
3. The transcript, annotated. Your actual words, with the moments that drove the score highlighted — the sentence where you finally answered the actual question, the spot where you trailed off, the follow-up where you contradicted something you said two minutes earlier.
4. Specific, quotable feedback. Not "good job" — actual sentences referencing what you said: "You described the what of the migration in detail but never explained why Redis over Postgres, which is the part the follow-up was fishing for."
5. One next action. Every report ends with a single, concrete thing to drill before your next session — not a list of twelve improvements that overwhelms you into doing none of them.
That structure is deliberate. A number with no breakdown is a verdict. A number with a breakdown is a diagnosis — and diagnoses are things you can act on.
It's worth pausing on why those five layers exist in that specific order, because the order isn't arbitrary. The overall score is first because it's what you'll glance at in three seconds on your phone between meetings — it needs to exist, but it's deliberately the least informative layer of the five. The dimension bars come next because they answer the very next question anyone asks after seeing a number: "okay, but why?" The annotated transcript exists because dimension bars alone are still an abstraction — "structure: 4/10" doesn't tell you which sentence cost you the points, but the transcript does. The written feedback exists to translate the annotated transcript into plain English, because not everyone wants to re-read their own transcript line by line every time. And the single next action exists because all four of the previous layers, taken together, can still produce decision paralysis — too much information, not enough clarity on what to actually do Monday morning before your next mock. Each layer solves the problem the previous layer couldn't.
How the 1-10 scoring actually works
Here's the part worth being precise about, because it's also the part most people get wrong: Ari scores your interview performance on a 1-10 scale. This is distinct from a completely different, much smaller widget — a 1-5 emoji rating you might see after a session asking "how did that feel?" (😩 to 😄). That emoji thing is a satisfaction survey, like the one your food delivery app shows you. It has nothing to do with how you performed. If you've seen both somewhere in the product and assumed they were the same metric measured two ways, they're not — the 1-10 is the performance grade; the 1-5 emoji is "did you enjoy the experience," full stop.
The 1-10 itself isn't generated by asking the model "rate this answer 1 to 10" and trusting whatever number falls out — that approach is exactly the kind of mushy, inconsistent black box that makes AI scoring untrustworthy in the first place, and it's worth naming because it's how a lot of "AI feedback" tools actually work under the hood. Greenroom's scoring is rubric-anchored: each dimension has explicit criteria for what a 2, a 5, and a 9 look like, derived from how real technical and behavioral interviewers actually grade, and the model is graded against those anchors rather than free-floating on vibes.
Concretely, here's what separates score bands on, say, the technical correctness dimension:
- 1-3: Factually wrong, or so vague the interviewer can't tell if you understand the concept at all.
- 4-6: Directionally correct, but missing a key mechanism, or correct only because you got lucky with how the question was phrased.
- 7-8: Correct, with the right mechanism named, but didn't anticipate the obvious follow-up.
- 9-10: Correct, mechanism named, and you proactively addressed the edge case or trade-off the follow-up was going to ask about anyway.
Communication clarity, structure, follow-up depth, and confidence signals each have their own version of this ladder. That's the actual answer to "how does the AI mock interview scoring work" — it's not one model improvising a number, it's five separate rubric-anchored judgments rolled into one.
The five dimensions, in plain terms
Technical correctness
Did you actually get the substance right? This is the dimension closest to a traditional grading key — is the data structure you named the right one, is the algorithm's complexity what you claimed, does the system design hold up under the follow-up about scale. It's graded against what's actually true, not against how confidently you said it (confidence is its own, separate dimension below — confidently wrong still scores low here).
Communication clarity
Could a stranger follow your answer without rewinding? This dimension grades structure of delivery, independent of correctness: did you lead with the answer (BLUF — bottom line up front) or bury it under three minutes of preamble; did you use signposting ("there are two parts to this — first... second..."); did your sentences resolve, or did you trail off into "...so yeah, that's basically it." A technically perfect answer that rambles for four minutes before landing the point scores lower here than a tighter answer that gets there in ninety seconds — because in a real interview, the rambling answer is the one that gets cut off by a confused interviewer before you ever land the point.
Structure / STAR adherence
For behavioral and "tell me about a time" questions specifically, this grades whether you used a recognizable scaffold — Situation, Task, Action, Result — rather than a meandering anecdote. The most common failure here isn't "no structure at all," it's stopping at Action and never stating a Result, so the interviewer is left to guess whether your story actually worked out. We cover this scaffold in depth in behavioral STAR answers for senior engineers if you want the long version.
Depth on follow-ups
This is the dimension most candidates underestimate, and it's the one that does the most work distinguishing a 6 from a 9. Ari doesn't ask a question and grade your first answer in isolation — it asks a real follow-up, the way a real interviewer would, and grades how you handle being pushed. Did you have a real second layer to your answer, or did the follow-up reveal that your first answer was the entire depth of your understanding? A surface-level first answer that survives a good follow-up scores higher than a polished first answer that collapses the moment someone asks "why" a second time.
Confidence and filler-word density
This grades delivery mechanics: hedging language ("I think, um, maybe, sort of"), filler-word density (the "um/like/so" count per minute), and pacing. It is deliberately the lowest-weighted dimension of the five, on purpose — a slightly nervous delivery of a technically excellent answer should still score well overall, and Greenroom's weighting reflects that. This dimension exists to flag a pattern (you say "I think" before every claim, even ones you're sure of), not to penalize normal human nervousness, which every real interview has anyway.
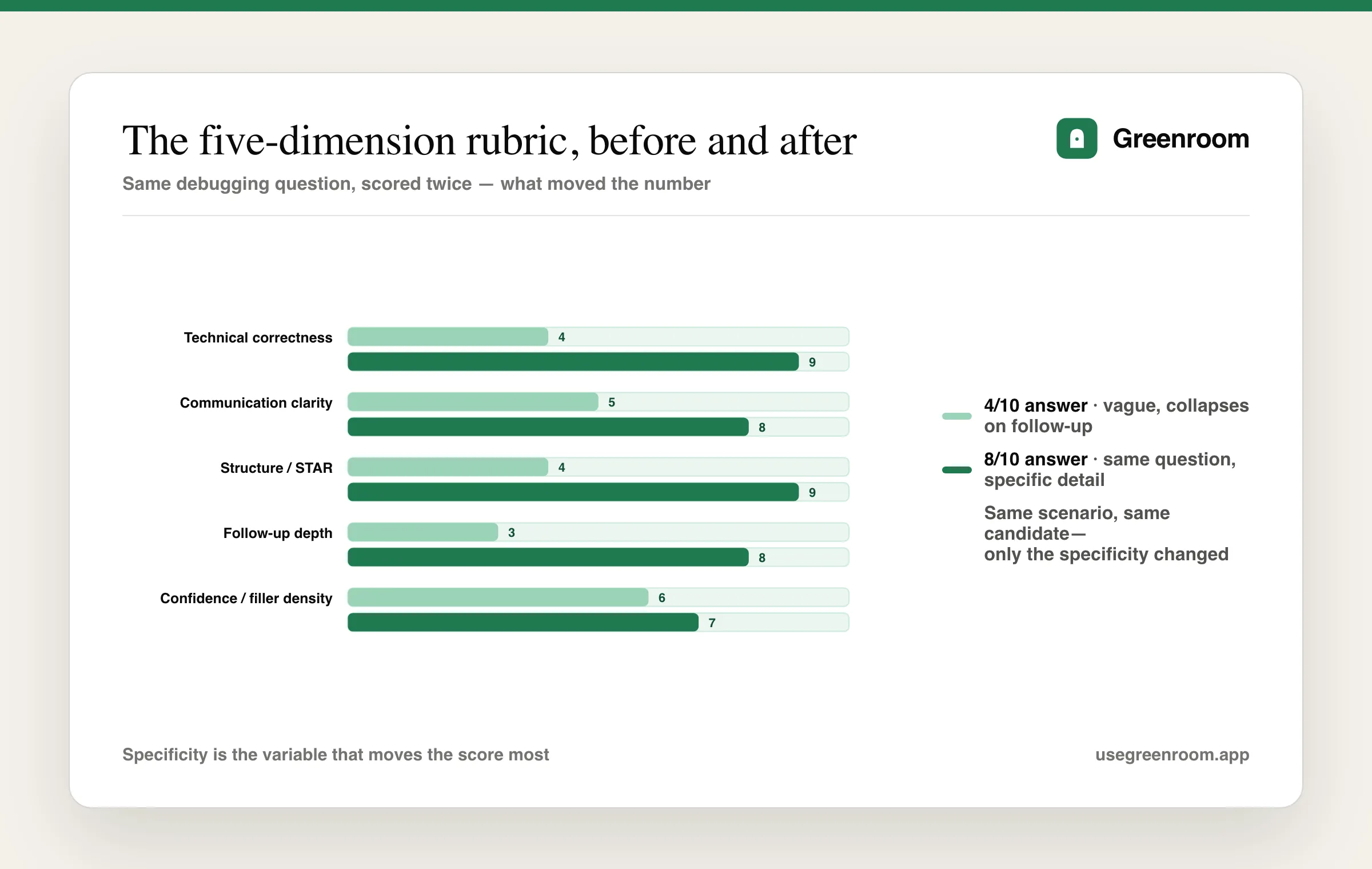
A worked example: the same question, 4/10 vs 8/10
Theory is fine, but the thing that actually builds trust is seeing the rubric applied to one real question, twice — once badly, once well — so you can see exactly what moved the number. Here's a question that comes up constantly in backend and full-stack interviews: "Walk me through a time you had to debug a production issue under pressure."
The 4/10 answer
"Yeah so we had this bug in production, it was pretty bad, customers were complaining. I looked at the logs and eventually found it was like a database thing. I fixed it and deployed the fix and it was good after that. It was stressful but we got through it."
What happened on the rubric, dimension by dimension:
- Technical correctness: 4/10. "A database thing" isn't a diagnosis — there's no named root cause, no mechanism. The interviewer (and Ari) cannot tell if the candidate actually understood the bug or got lucky with a restart.
- Communication clarity: 5/10. Linear and easy enough to follow, but vague — "pretty bad," "eventually," "good after that" are placeholders, not information.
- Structure: 4/10. There's a Situation and a vague Action, but no real Task (what was the candidate's specific responsibility?) and the Result is a flat "it was good," with no measurable outcome.
- Depth on follow-ups: 3/10. When Ari followed up with "What specifically in the database was causing it?", the answer was "I don't remember the exact details, but it was something with the queries" — confirming the first answer's depth was the entire depth.
- Confidence: 6/10. Delivery itself was fine — no excessive hedging — it's the content that was thin, not the nerves.
Weighted overall: 4/10.
The 8/10 answer, same question
"At my last internship, our checkout service started timing out for about 8% of requests during a flash sale — I was the one on call. I pulled the APM traces first and saw the timeouts were all hitting one endpoint that did a synchronous call to inventory. Inventory's database had a missing index on a column we'd started filtering on after a recent feature shipped, so every query was doing a full table scan under load. I added the index, but more importantly I also added a query timeout and a circuit breaker so a slow dependency couldn't cascade into a full outage next time. We went from 8% error rate back to under 0.1% within twenty minutes of the index going live, and the circuit breaker meant a similar issue three weeks later degraded gracefully instead of repeating the outage."
Same scenario archetype, same general shape — but look at what changed on the rubric:
- Technical correctness: 9/10. Named root cause (missing index causing a full table scan), named mechanism (synchronous dependency call cascading), and a fix at two levels (the immediate fix and the systemic fix).
- Communication clarity: 8/10. Specific numbers throughout (8%, twenty minutes, 0.1%, three weeks) instead of "pretty bad" and "eventually" — numbers are doing the work vague adjectives can't.
- Structure: 9/10. Clean STAR: Situation (flash sale, 8% timeouts), Task (on-call engineer diagnosing it), Action (traces → root cause → immediate fix → systemic fix), Result (quantified recovery, plus evidence the systemic fix worked later).
- Depth on follow-ups: 8/10. When Ari followed up with "why a circuit breaker and not just a retry?", the candidate explained that retries on an already-overloaded dependency make the cascade worse, not better — a real second layer of understanding, not an "I don't remember."
- Confidence: 7/10. Steady delivery, no real hedging — slightly lower than a 9 only because pacing was a touch fast in the back half, per Ari's note.
Weighted overall: 8/10.
Notice what didn't change: the underlying competence of "an engineer who knows how to debug a production incident" was probably similar in both tellings — the gap is almost entirely in what got said out loud. That's the actual lesson of the worked example, and it's the single most important thing this whole post is trying to communicate: the score isn't grading whether you're good at your job. It's grading whether your answer proved it. Those are related but not identical, and the entire value of practicing with feedback is closing that gap before a real interviewer is the one left unconvinced.
Why this isn't just vibes — and why a black box wouldn't earn your trust anyway
It's fair to be skeptical of any product that says "trust our AI's judgment." So here's the honest version of why this rubric-based approach is meaningfully different from a model just intuiting a score:
The rubric is fixed, not regenerated per answer. The 1-3/4-6/7-8/9-10 anchors per dimension exist before your answer does. The model isn't inventing standards on the fly to match whatever you happened to say — it's checking your answer against a standard that was the same yesterday and will be the same tomorrow. That's what makes two different candidates' 7/10s comparable to each other.
Every score has a visible reason. If a dimension score seems off to you, the report shows you the line in your transcript the score is anchored to. You're never just told "6/10, trust us" — you can trace the number back to a specific moment in your own answer and agree or disagree with the read.
The follow-up is real, not theater. A huge amount of what makes Greenroom's scoring credible is that the follow-up question is generated based on what you actually said, the same way Ari calibrates difficulty to your level — it's not a scripted "and how did that make you feel" stock question. If you mention Redis in passing, the follow-up might be about Redis. That's the same mechanism a sharp human interviewer uses to find out if your first answer was the whole iceberg or just the tip, and it's a big part of why structured AI interviews outperform unstructured ones for consistency.
None of that makes the system perfect — more on that below — but it's the difference between "an algorithm graded you" and "an algorithm graded you against a standard it can show you, on a question it generated based on your own words."
How Greenroom's feedback compares to the alternatives
If you're choosing how to spend your prep time, the AI feedback report is competing with a few real alternatives, and it's worth being honest about where each one actually helps.
A friend who says "you did fine." This is the most common form of interview feedback in the world, and it's almost worthless — not because friends are bad people, but because "fine" carries zero information about which dimension was fine. Was it technically fine? Was it fine-but-rambling? Did they even notice you skipped the Result in your STAR answer? A friend giving feedback after watching you talk for thirty minutes, off the cuff, with no rubric, is doing the verbal equivalent of grading an essay by gut feel — which is exactly the "vibes" problem this whole post is trying to get away from. Greenroom's structured, dimension-by-dimension breakdown exists specifically because "you did fine" doesn't tell you what to fix.
Self-recording and reviewing alone. Recording yourself and watching it back is genuinely useful — you'll catch a filler-word habit or a posture issue you didn't know you had. But you're grading your own performance with the same brain that just produced it, which is a real blind spot: you already know what you meant to say, so a vague answer sounds more complete in your own ears than it would to a stranger hearing it cold. An external rubric catches the gap between what you meant and what you actually said.
Generic "rate my answer" ChatGPT prompting. Pasting your answer into a chat window and asking "is this good?" gets you a response, but it's grading text you typed calmly, after the fact, with time to edit — not a spoken answer produced live, under the mild pressure of a real follow-up question you didn't expect. It also doesn't have a fixed rubric across sessions, so your "8/10" from ChatGPT on Tuesday and your "8/10" from ChatGPT on Thursday aren't actually measuring the same thing, because there's no anchor underneath either number — it's a different improvisation each time you ask. Greenroom's spoken, follow-up-driven, rubric-anchored format is built to close exactly that gap — it's also why coding interview communication tips emphasize practicing out loud over reading prepared answers silently.
Question-dump platforms (GeeksforGeeks-style lists, LeetCode discuss threads). These are genuinely useful for building a question bank and seeing patterns, but they give you zero feedback on your delivery of an answer — you're reading someone else's solution, not getting graded on your own. They solve the "what might get asked" problem; they don't solve the "how did I actually sound answering it" problem at all, which is a different and arguably harder problem for most candidates past the junior level.
Other AI mock-interview platforms. A growing number of platforms now offer some flavor of AI feedback, and the honest differentiator to look for, regardless of which one you use, is whether the score comes with a visible rubric and a real follow-up question — or whether it's a single number with a paragraph of generic encouragement underneath. If a platform's report can't show you why a 6 is a 6, you have no way to know if the number means anything at all.
A real human interviewer or career coach. This is the one alternative this post wants to be completely honest about, because it's the strongest one, and it's covered fully in the next section.
What AI feedback genuinely cannot do — the limits, stated plainly
Marketing copy that says "AI feedback is exactly as good as a human's" is lying to you, and a candidate who's been burned once by oversold AI tools will smell it instantly. So here's the real limits list, stated without hedging:
It cannot replace a real offer-stage human read. A hiring panel isn't just grading your answer to "tell me about a challenging project" — they're weighing team fit, communication style against their specific team's culture, and a dozen subjective signals that don't reduce to a rubric, because the actual decision they're making ("would I want to work next to this person") isn't a rubric-shaped question. AI feedback is preparation infrastructure. It is not, and shouldn't be marketed as, a substitute for the actual humans who'll eventually decide whether to extend an offer.
It can over-weight phrasing quirks. A candidate with a strong accent, a non-native English speaking pattern, or simply an unusual but coherent way of structuring sentences can occasionally get under-scored on communication clarity for how something was said rather than what was said, even with rubric anchoring designed to minimize this. This is a known, documented failure mode in NLP-based scoring systems broadly — assessment researchers (the kind of work bodies like SIOP, the Society for Industrial and Organizational Psychology, study closely) have flagged this exact risk in AI-assisted hiring tools for years, and it's why Greenroom weights communication clarity below technical correctness and follow-up depth in the overall score, rather than letting delivery quirks dominate.
It can under-weight unconventional but valid answers. If you solve a system design question with an approach that's correct but unusual — not the textbook answer the rubric anchors were calibrated against — the model can occasionally score it lower than a more conventional-but-equally-valid approach would score. This is an inherent risk of any rubric-based system, human or AI: rubrics reward legibility, and legibility sometimes under-rewards genuine originality.
It doesn't know your specific target company's bar. A 7/10 on Greenroom's general rubric doesn't map cleanly to "you'll pass Google's bar" or "you'll pass a seed-stage startup's bar" — those bars are genuinely different, and no general-purpose feedback tool should claim otherwise.
A single low score from one off night isn't a verdict. If you bomb a session because you were tired, distracted, or the question happened to hit a weak spot, that 4/10 is real information about that session — not a permanent assessment of your ability. The fix is more reps, not despair.
It can be gamed in narrow, brittle ways. If you know the rubric rewards quantified results, you could technically invent a fake number to insert into a story instead of remembering the real one — "we improved load times by 47%" sounds specific whether or not it's true. The rubric rewards the shape of a well-told answer, and it can't independently verify every fact inside it the way a reference check or a portfolio review eventually would. This is a limit worth being honest about rather than glossing over: specificity is a strong proxy for depth of understanding, but it is a proxy, not a polygraph.
It scores the session it sees, not your full history. A single mock interview is a sample of one moment, with one set of questions and one mental state. Two candidates with identical underlying skill can land different scores on the same day for reasons that have nothing to do with ability — one happened to get a follow-up they'd specifically prepped for, the other didn't. This is exactly why the "track the trend, not the single session" guidance later in this post isn't just a nice suggestion — it's a direct mitigation for a real statistical limit of any single-session score.
Naming these limits isn't an admission that the product doesn't work — it's the opposite. A scoring system that can tell you exactly where it's confident and where it might be wrong is more trustworthy than one that claims perfect objectivity, the same way a doctor who says "this test has a 90% accuracy rate" is more credible than one who says "trust me completely." If you want a deeper look at how Greenroom thinks about the integrity side of AI-graded interviews more broadly — including how it handles cheating and unusual answer patterns — that's covered in cheating signals and integrity.
How to actually use the report instead of just reading the number
This is the part most candidates skip, and it's the part that actually moves your interview performance. Reading "6/10" and closing the tab is the single biggest waste of a feedback report's value. Here's the actual workflow:
1. Read the dimension breakdown before the overall score even registers. Train yourself to scan the five bars first. A 6/10 overall that's a 9 on technical correctness and a 3 on structure is a completely different problem than a 6/10 that's even across the board — and they need completely different fixes.
2. Find the lowest single dimension and drill only that one next. Trying to fix all five dimensions in your next session is how you fix none of them. If structure is your weak bar, your only goal in the next mock is finishing every behavioral answer with an explicit, quantified Result — ignore everything else this round.
3. Re-read the annotated transcript, not just the summary paragraph. The summary paragraph is the headline; the transcript annotations are where the specific evidence lives. If the report flags a moment where you trailed off, go find that exact sentence and rewrite it in your head before your next attempt.
4. Re-attempt the same or a similar question within the week. The worked example above wasn't theoretical — it's the realistic gap between attempt one and attempt three or four on a similar prompt, once you know specifically what the rubric is rewarding. Improvement compounds fastest when the gap between attempts is short enough that the feedback is still fresh.
5. Track the trend, not the single session. One report is a data point. Five reports across two weeks are a trend line, and the trend line is the thing actually worth caring about — a string of follow-up-depth scores climbing from 4 to 5 to 7 tells you the thing you're drilling is working, far more reliably than any single session's number.
6. Use the score to decide what to drill, not how to feel about yourself. This sounds like a platitude, but it's the practical crux of the whole report: a 4/10 is diagnostic data about one session's structure dimension, not a referendum on whether you're cut out for the job. Treat it like a workout app's heart-rate chart, not like a report card from a teacher who doesn't like you.
7. Build a small "specifics bank" before your next session, not during it. Since the gap between a 4 and an 8 is almost always missing detail rather than missing competence, the highest-leverage prep move is boring and unglamorous: before your next mock, write down three to five real numbers from your own work history — an error rate, a timeline, a percentage, a team size — so they're available to you under pressure instead of needing to be invented on the spot. Candidates who do this consistently see their technical correctness and structure scores jump within two or three sessions, because the missing ingredient was never speaking ability, it was retrievable memory.
8. Don't over-index on a single dimension at the expense of the others. It's tempting, once you notice your structure score is your weakest, to drill STAR scaffolding so hard that your delivery starts sounding robotic and over-rehearsed — at which point communication clarity quietly starts slipping even as structure improves. The goal of using the report well is raising your weakest dimension back toward your others, not pushing one dimension past the rest and creating a new, different imbalance.
A second worked example: a behavioral question, not a technical one
The debugging example above is technical, and it's tempting to assume rubric-based scoring only really works for questions with a clean "right answer" underneath. So here's a second worked example on a pure behavioral question, where there's no objectively correct root cause to name — just whether the story is told well enough to be believed.
The question: "Tell me about a time you disagreed with a teammate's technical decision."
The 4/10 answer
"So there was this one time my teammate wanted to use a certain library and I didn't really agree with it. I tried to explain my point but they kind of pushed back. We ended up using their approach anyway. It worked out okay I guess, but I still think my way might have been better honestly."
Walking through the rubric: technical correctness isn't really in play here (it's a behavioral question), but structure scores low (3/10) — there's a Situation and a thin Action, but no real Task framing (what was actually at stake?) and the Result ("it worked out okay I guess") actively undercuts the story instead of resolving it. Communication clarity sits around 4/10 — "a certain library," "kind of pushed back," "I guess" are all hedges that strip the story of any concrete detail an interviewer could evaluate. Depth on follow-ups lands at 3/10: when Ari asked "what was the actual disagreement about, technically?", the candidate said "I don't totally remember the specifics, just that I had a different opinion" — which is the same collapse pattern as the technical example earlier. The lingering "I still think my way might have been better" at the end also reads as mildly defensive rather than reflective, which is exactly the kind of close-out line that makes an interviewer wonder how this person handles being overruled in a real team setting.
Weighted overall: 4/10.
The 8/10 answer, same question
"On my last team, I wanted to add a caching layer in front of our recommendations API because we were seeing repeat queries hammering the database during peak hours. A teammate pushed back — he was worried a cache would serve stale recommendations right after a user's behavior changed, which mattered a lot for our product. Instead of just arguing the point, I proposed we A/B test it: ship the cache with a short 90-second TTL, and watch both database load and recommendation staleness complaints for a week. Database load dropped about 40% and we got zero staleness complaints, so we shipped it permanently. The disagreement itself ended up being useful — his concern was legitimate, and the short TTL was a direct response to it, not something I'd have landed on if I'd just pushed my original plan through."
On the rubric: structure scores 9/10 — clean STAR, and crucially the Result resolves the actual disagreement (40% load drop, zero complaints) rather than just describing what happened. Communication clarity scores 8/10 — concrete numbers (40%, 90-second TTL, one week) replace the vague hedging from the 4/10 version entirely. Depth on follow-ups scores 8/10: when asked "what would you have done if the staleness complaints had shown up?", the candidate explained they'd have shortened the TTL further or scoped caching to lower-volatility recommendation categories — a real second layer of contingency thinking, not a shrug. Notably, this answer also scores well on a dimension that's easy to miss: it frames the disagreement as something that improved the outcome, rather than something the candidate "won" or "lost" — which is exactly the maturity signal a real interviewer is fishing for with this question in the first place.
Weighted overall: 8/10.
The pattern repeats from the technical example: the gap isn't a different story, it's the same story told with the specifics that were always available in the candidate's memory, just not volunteered out loud under the mild pressure of being asked live. That's the whole reason rehearsal works — the second time through a story, you remember the numbers you forgot to mention the first time.
Why specificity is the variable that moves the score most
Both worked examples above point at the same underlying lever, and it's worth naming directly because it's the single highest-leverage thing to drill if you only have time to fix one habit: vague language is almost always a symptom of an answer that was never fully thought through, not just a delivery problem. "A database thing" isn't vague because the candidate is bad at talking — it's vague because they never actually nailed down the root cause in their own head, so there was nothing more specific available to say. "It worked out okay I guess" isn't vague phrasing — it's a story that never had a quantified ending because the candidate never went back to check what actually happened after the disagreement was resolved.
This matters because it changes how you should prepare. If you treat low scores as a speaking problem, you'll practice "sounding more confident," which mostly produces confidently vague answers — somehow worse, because now the vagueness is wrapped in false certainty. If you treat low scores as a thinking problem, you go back to your actual project history, dig up the number you forgot (the error rate, the timeline, the percentage improvement), and the next telling of the story is specific because you did the work of remembering it, not because you practiced a more assertive tone of voice.
This is also exactly why a follow-up question is so diagnostic. A follow-up doesn't just test whether you can keep talking — it tests whether the specific detail you're missing was ever actually known to you. "I don't remember the exact details" under a follow-up is a different failure than "I'm not sure how to phrase this" — the first means the depth was never there; the second is a delivery issue that's much easier to fix. Greenroom's report tries to distinguish between these two failure modes explicitly, because the fix for each is completely different, and conflating them is how a lot of generic feedback ends up unhelpful — telling someone to "be more confident" when their actual problem was never remembering the root cause in the first place.
Frequently asked questions
Is Greenroom's AI interview score 1-10 or 1-5?
Greenroom scores interview performance on a 1-10 scale. There's a separate, much smaller 1-5 emoji widget that sometimes appears after a session asking how the experience felt — that's a satisfaction survey, not a performance score, and the two are never combined or confused in the actual report.
How is the AI mock interview score calculated?
Each answer is graded against a fixed, rubric-anchored standard across five dimensions — technical correctness, communication clarity, structure/STAR adherence, depth on follow-ups, and confidence/filler-word density — and the overall 1-10 score is a weighted roll-up of those five, not a single free-floating judgment. The rubric anchors (what a 2 vs a 5 vs a 9 looks like) are fixed in advance, so the same standard applies across every session.
Can I trust an AI to grade my interview answers fairly?
Mostly, with real limits worth knowing. The rubric-anchored, transcript-visible approach is meaningfully more trustworthy than an unstructured "rate this 1-10" black box, because every score traces back to a specific moment in your transcript you can check yourself. But AI feedback can occasionally over-weight phrasing quirks or under-weight unconventional but valid answers, and it can't replace the subjective, team-fit judgment of a real human hiring panel at the offer stage.
What's the difference between a 4/10 and an 8/10 answer?
Almost always specificity, not raw competence. A 4/10 answer tends to use vague placeholders ("a database thing," "it was pretty bad," "it was good after that") and collapses under a follow-up question. An 8/10 answer to the same prompt names the actual root cause, quantifies the outcome, and has a real second layer of understanding that survives being pushed on. The underlying skill gap between the two is often smaller than the score gap suggests — the difference is what got said out loud.
Does a low score on one mock interview mean I'm not ready for the real thing?
No. One session's score is information about that session, not a verdict on your overall readiness — fatigue, an unfamiliar question, or a single rough follow-up can all drag a single session down. What matters is the trend across multiple sessions: if your follow-up-depth or structure scores are climbing over several mocks, that's the real signal, far more than any one number.
Can the AI feedback report replace a real human mock interviewer?
Not entirely, and it shouldn't claim to. It's excellent at consistent, rubric-anchored, judgment-free repetition — the kind of volume practice a busy human mentor can't realistically give you every week. It's not a substitute for the subjective, culture-fit, offer-stage judgment of an actual hiring panel, which weighs things no rubric fully captures. Use AI feedback for volume and structure; use real humans for the final-round gut check before a high-stakes interview.
Why did my score drop on a question that felt easier than last time?
Usually one of three things: the follow-up question this time pushed harder on a specific detail than last time's follow-up did, your answer this time was technically fine but less structured than your best previous attempt, or you were simply less prepared on the specific angle the follow-up took, even if the surface-level question felt familiar. A single session's score is noisy by nature; if a drop repeats across two or three sessions on the same question type, that's the signal worth actually investigating. A one-off dip usually isn't.