
Somewhere around minute twenty of a backend interview, someone asks you, "why did your search for 'running shoes' just return a product called 'Running Man (2013 film)'?" and you realize, with the slow horror of someone watching their own car roll downhill, that you never actually configured an analyzer — you just typed text into a field and assumed Elasticsearch would read your mind. It will not. It will, however, very confidently and very fast return you the wrong thing, which is somehow worse than being slow about it.
Elasticsearch shows up in interviews for search infrastructure, logging/observability platforms (the "E" in the ELK stack), e-commerce catalogs, and increasingly RAG-adjacent retrieval systems — and the questions split cleanly into two buckets: how it stores and finds data (the inverted index, sharding, replication) and how it ranks results (relevance scoring, query types). This guide covers the Elasticsearch interview questions that actually come up — indexing, sharding and cluster design, queries, relevance scoring, and the operational gotchas — with real answers and the reasoning behind each.
What is Elasticsearch, and how is it different from a relational database?
Elasticsearch is a distributed, document-oriented search and analytics engine built on top of Apache Lucene. Unlike a relational database, which is optimized for exact-match lookups and transactional consistency, Elasticsearch is optimized for full-text search and fast filtering/aggregation across large volumes of semi-structured JSON documents. It trades strict, immediate consistency (a write isn't searchable instantly — more on this below) for speed and flexible, schema-light querying. The interview signal here: can you say when you'd reach for it — full-text search, log aggregation, fuzzy/typo-tolerant search, faceted filtering — versus when a relational database or a dedicated key-value store is the better tool.
Elasticsearch indexing questions
What is an inverted index, and why does it make search fast?
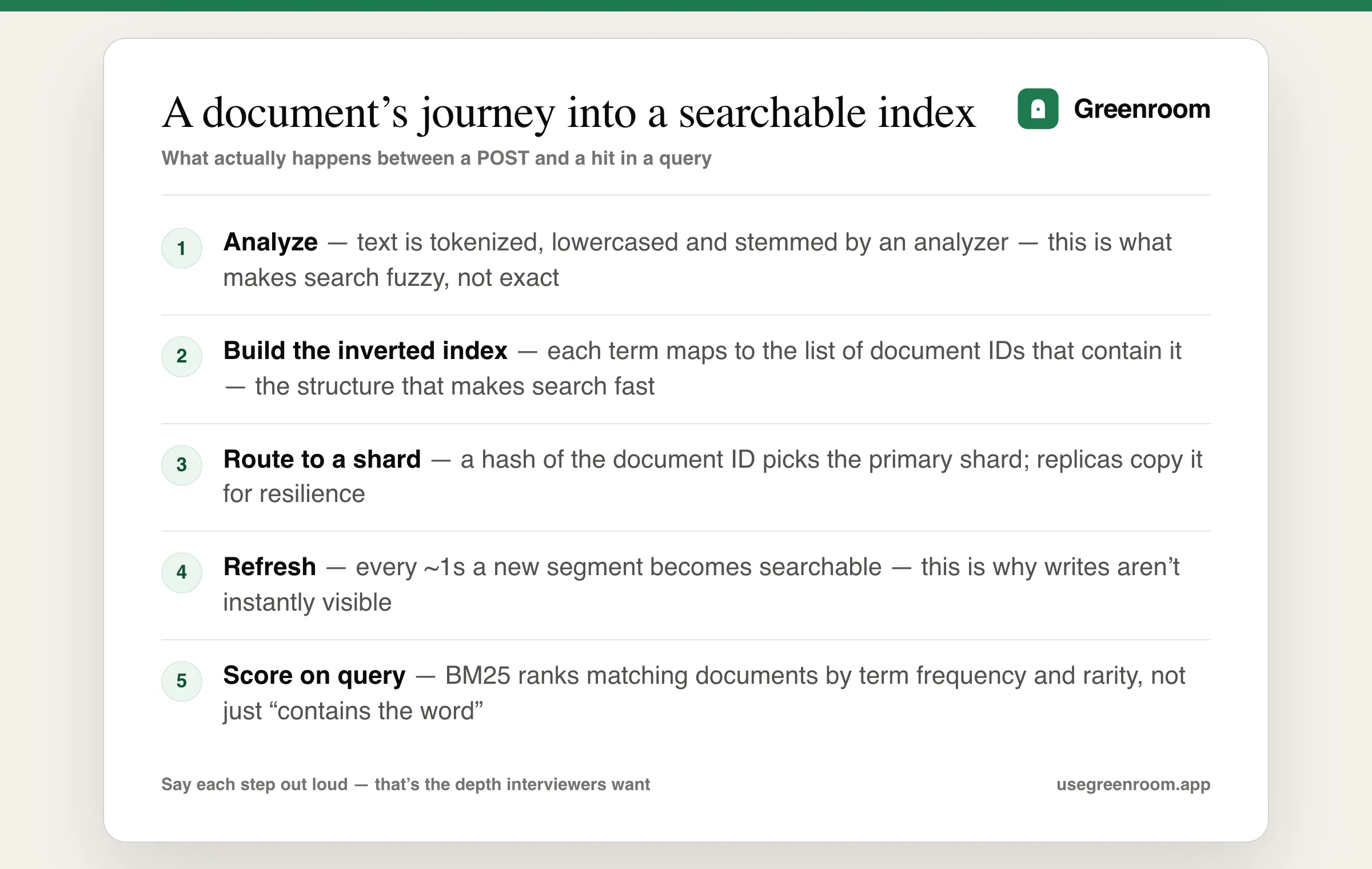
A traditional database index maps a row to its values; an inverted index does the opposite — it maps each unique term to the list of documents (and positions) that contain it. Searching for "running shoes" becomes a fast lookup of the term "running" and the term "shoes" in this map, followed by intersecting/scoring the matching document lists, instead of scanning every document's text. This is the single structural idea that makes full-text search at scale viable, and interviewers will often just ask you to explain it from scratch.
What does an analyzer do, and why does it matter?
An analyzer is the pipeline that turns raw text into the terms that actually go into the inverted index: a tokenizer splits text into words, then a chain of token filters lowercases them, removes stop words, and applies stemming (so "running" and "run" can match the same root). This is exactly why a misconfigured or missing analyzer causes search to feel "dumb" — without it, "Running" and "running" are different terms, and a search for one won't find the other. Getting this question right means explaining the pipeline, not just naming the word "analyzer."
What's the difference between a text field and a keyword field?
text fields are analyzed — broken into searchable terms, good for full-text matching ("find documents containing the word 'running'"). keyword fields are stored as-is, exact-match only — good for filtering, sorting, and aggregations ("show me all products where category.keyword == 'Footwear'"). A very common real bug: trying to aggregate or sort on a text field and getting an error or nonsense results, because aggregations need the exact, unanalyzed value a keyword field provides. Mapping a field as both (text with a keyword sub-field) is the standard fix, and naming that pattern unprompted is a strong signal.
What happens between indexing a document and being able to search for it?
A new or updated document first goes into an in-memory buffer and a transaction log (the translog, for durability). It only becomes searchable after a refresh — by default, roughly every second — writes a new, immutable segment to disk that Lucene can search. This is why Elasticsearch is described as near real-time, not real-time: there's a small, configurable delay between a write and that write being searchable. Periodically, smaller segments are merged into larger ones in the background to keep search efficient, since searching across many tiny segments is slower than searching fewer, larger ones.
Elasticsearch sharding and cluster design questions
What is a shard, and why does Elasticsearch shard data?
A shard is a self-contained, independent instance of a Lucene index — Elasticsearch splits an index into multiple primary shards so the data and the query load can be spread across multiple nodes, enabling horizontal scale beyond what a single machine could hold or serve. Each primary shard can have one or more replica shards — exact copies that provide both fault tolerance (a node going down doesn't lose data) and extra read throughput (queries can be served from replicas too).
How do you decide how many shards an index should have?
This is a classic "there's no single right number, but show me you understand the trade-off" question. Too few shards limits how much you can scale out and can create oversized shards that are slow to recover after a failure. Too many shards wastes resources — each shard has real overhead (file handles, memory, cluster state to track), so an over-sharded cluster can be slower and less stable than a right-sized one, especially at small data volumes. The honest, practical answer: think in terms of target shard size (commonly guided toward roughly 10–50GB per shard as a starting heuristic, not a hard rule) and expected growth, and remember that primary shard count can't be changed without reindexing — it has to be planned, not bolted on later.
What happens during a node failure?
If a node holding a primary shard goes down, Elasticsearch promotes one of that shard's replicas to be the new primary, and the cluster works to allocate a new replica elsewhere to restore full redundancy — all without requiring a restart of the whole cluster, as long as enough nodes and replicas exist to do so. This is the operational payoff of replication, and interviewers want to hear you connect "why replicas exist" to "what concretely happens when a node dies," not just the definition.
What's the difference between routing and rebalancing?
Routing determines which shard a given document is written to or read from — by default, a hash of the document's _id. Rebalancing is the cluster moving shards between nodes over time to keep load evenly distributed, which happens automatically as nodes join, leave, or as data grows unevenly. A nuance worth naming: custom routing (forcing all of one customer's documents onto the same shard, for example) can improve query performance for that access pattern, but it also risks creating "hot" oversized shards if that customer's data grows disproportionately.
Elasticsearch query and relevance questions
What's the difference between a term query and a match query?
A term query looks for an exact value, bypassing the analyzer — appropriate for keyword fields. A match query runs the search text through the same analyzer used at index time before matching — appropriate for text fields, since it lets "Running" match "running." Using term against an analyzed text field is a classic, very common bug: it often silently returns zero results because the exact string you searched was never stored as a term — only its analyzed (lowercased, stemmed) pieces were.
How does Elasticsearch rank results? Explain relevance scoring.
By default, Elasticsearch uses BM25, a refinement of the older TF-IDF model. The intuition worth being able to explain out loud: a term that appears more often in this specific document (term frequency) raises the score, but a term that appears in almost every document in the index (low inverse document frequency, like "the" or "product") contributes very little, since it's not actually distinguishing this document from others. BM25 also normalizes for document length, so a short, focused document isn't unfairly penalized against a long one that happens to repeat the term more times. The follow-up to expect: "how would you boost one field over another" — answered with field-level boosting (e.g., weighting a title match higher than a description match) inside a bool/multi_match query.
What's the difference between a filter and a query context in a bool query?
Both narrow results, but a query context contributes to the relevance score (how well something matches), while a filter context is a binary yes/no (does it match at all) and is not scored — and critically, filter clauses are cacheable and generally faster, since there's no scoring math to do. The practical rule interviewers want to hear: anything that's a hard yes/no condition (a date range, a status flag, a category) belongs in filter; anything that should influence ranking belongs in query/must.
{
"query": {
"bool": {
"must": [
{ "match": { "title": "running shoes" } }
],
"filter": [
{ "term": { "category.keyword": "Footwear" } },
{ "range": { "price": { "lte": 5000 } } }
]
}
}
}What is aggregation, and how is it different from a SQL GROUP BY?
Aggregations let you compute metrics (counts, averages, min/max) and bucket documents (by term, date range, histogram) over your search results — conceptually similar to GROUP BY, but designed to run efficiently over the same near-real-time, distributed index that powers search, often alongside a query in a single request (e.g., "show me matching products, and also a price-range histogram of all matches"). The nuance to mention: aggregations operate on the documents matching the query/filter context, so a faceted-search UI (search results plus filter counts) is naturally one Elasticsearch request, not two separate systems.
Elasticsearch vs. other prep approaches
A GeeksforGeeks-style "Elasticsearch interview questions" list will hand you the term "BM25" without ever making you explain why a rare term should score higher than a common one when someone pushes back with "but doesn't 'the' appear in every relevant document too?" — and that follow-up is exactly where a memorized answer falls apart live. LeetCode doesn't cover this material at all; Elasticsearch knowledge is closer to a systems/infrastructure interview than an algorithms one. Reading the official Elasticsearch documentation (genuinely excellent, and worth doing) is necessary but not sufficient — recognizing a correct explanation when you read it is a different skill from producing one yourself, unprompted, when an interviewer asks "walk me through what happens between a write and a search hit."
Greenroom runs spoken mock interviews that ask exactly these kinds of follow-ups — "why would a term query against a text field return nothing," "what happens to in-flight searches during a node failure" — and gives feedback on how clearly you explained the mechanism, not just whether you named the right buzzword. Pair it with our backend developer interview guide and system design guide for the broader infrastructure context Elasticsearch usually sits inside.
How to prepare for an Elasticsearch interview
- Be able to explain the inverted index and the analyzer pipeline from scratch, not just name them — this single explanation underlies almost every other answer in the interview.
- Know the
textvs.keyworddistinction cold, including the real bug it causes (failed aggregations, zero-resulttermqueries) — this is one of the highest-frequency practical questions. - Practice explaining sharding trade-offs out loud — too few vs. too many shards, and why primary shard count can't be changed without reindexing.
- Know BM25's intuition, not the formula — term frequency raises the score, document frequency (commonness across the index) lowers it, and length is normalized.
- Practice the
filtervs.querycontext distinction and be ready to write a smallboolquery live, since this comes up as a hands-on exercise as often as a verbal question.
Frequently asked questions
What is Elasticsearch used for?
Elasticsearch is used for full-text search (product catalogs, content search), log and metrics aggregation (the ELK/Elastic Stack for observability), faceted/filtered search experiences, and increasingly as a retrieval layer in RAG-style AI applications. It's chosen over a relational database when fast full-text search, fuzzy matching, or large-scale aggregation across semi-structured data matters more than strict transactional consistency.
What is the difference between a text field and a keyword field in Elasticsearch?
A text field is analyzed into searchable terms (tokenized, lowercased, stemmed), making it suited for full-text matching. A keyword field stores the exact, unanalyzed value, making it suited for filtering, sorting, and aggregations. A common real-world bug is trying to aggregate or exact-match against a text field and getting wrong or empty results, since aggregations need the exact value a keyword field provides.
How does Elasticsearch rank search results?
By default, Elasticsearch uses the BM25 algorithm: a term that appears frequently within a specific document raises that document's score, while a term that appears across most documents in the index contributes little, since it doesn't help distinguish relevant documents. BM25 also normalizes for document length so short documents aren't unfairly penalized, and field-level boosting can be added to weight some fields higher than others.
What is a shard in Elasticsearch, and how many should an index have?
A shard is an independent Lucene index instance; Elasticsearch splits data into primary shards to scale horizontally across nodes, with replica shards providing fault tolerance and extra read capacity. There's no universal right number — too few limits scaling and creates large, slow-to-recover shards, while too many wastes resources — and a common heuristic is to target a reasonable shard size (often discussed around 10–50GB) based on expected data volume, since primary shard count cannot be changed without reindexing.
What's the difference between a filter and a query clause in a bool query?
A query/must clause contributes to the relevance score, while a filter clause is a binary yes/no match that isn't scored and is generally faster and cacheable. The practical rule: hard yes/no conditions like date ranges or status flags belong in filter, while anything that should influence how results are ranked belongs in query.
How should I prepare for an Elasticsearch interview?
Be able to explain the inverted index and analyzer pipeline from scratch, know the text vs. keyword distinction and the real bugs it causes, practice explaining sharding trade-offs and the BM25 relevance intuition out loud, and be ready to write a small bool query with filter and query clauses live, since Elasticsearch interviews test mechanism, not vocabulary.