
A bad phone screen rarely looks expensive in the moment. It's 30 minutes, one recruiter, one candidate. But the cost doesn't stay contained to that half hour — it leaks into every downstream stage of the loop. When you add up the wasted interviewer time, the scheduling overhead, the opportunity cost of slow-moving strong candidates, and the tail risk of a mis-hire that the screen should have caught, a poorly run phone screen costs a typical engineering org roughly $4,200 per role.
That number isn't a line item anyone sees. It's spread across calendars, Slack threads, and "let's just do one more round to be sure" decisions. Which is exactly why it persists — nobody owns it, so nobody fixes it.
Where the $4,200 actually comes from
Break a weak top-of-funnel screen into its parts and the cost becomes concrete:
- Wasted onsite interviewer time. Every weak candidate who clears a loose phone screen consumes 3–5 engineer-hours in later rounds. At a loaded senior-engineer cost, a single false positive can burn $600–$1,000 before anyone says "no."
- Recruiter and coordinator overhead. Re-screening, rescheduling, and chasing feedback on candidates who should have been filtered earlier is pure rework — and it scales with every req you open.
- Slower strong candidates. When the funnel is clogged with people who shouldn't be there, your best candidates wait — and the best candidates have other offers with shorter clocks.
- Mis-hire tail risk. The most expensive outcome is a mismatch discovered only after onboarding, where replacement cost dwarfs everything above.
Why phone screens are so inconsistent
The root problem is rarely the people. It's that most phone screens are unstructured by default. Two screeners ask different questions, weight answers differently, and write up their verdict from memory an hour later. There's no shared rubric, so "strong yes" from one screener and "strong yes" from another can mean completely different things. Add interviewer fatigue, time pressure, and the natural pull of gut feel, and you get a stage that's noisy precisely where you most need signal.
Noise at the top of the funnel is uniquely damaging because everything downstream inherits it. A clean onsite can't fix a screen that passed the wrong person — it can only spend money discovering the mistake.
The three failure modes
- Question drift. The screener improvises based on the résumé in front of them, so no two candidates are measured on the same thing.
- Halo and similarity bias. A candidate who shares the screener's background, vocabulary, or conversational rhythm reads as "sharp" regardless of job-relevant ability.
- Memory decay. The verdict is written after the next two meetings, so the record is a vibe, not evidence.
Where the cost compounds
The real drag appears when every downstream step quietly assumes the first screen already did its job. Hiring managers repeat basic qualification checks. Coordinators schedule extra interviews "to be safe." The team spends a debrief debating a candidate the process should have filtered an hour into the funnel, not five hours in. Each of these is individually small and collectively enormous.
And it gets worse at scale. A screen that's 10% too lenient doesn't cost you 10% more — it compounds, because each false positive multiplies across four or five onsite interviewers, each debrief, and each delayed decision that lets a strong candidate slip to a competitor.
What a good screen looks like
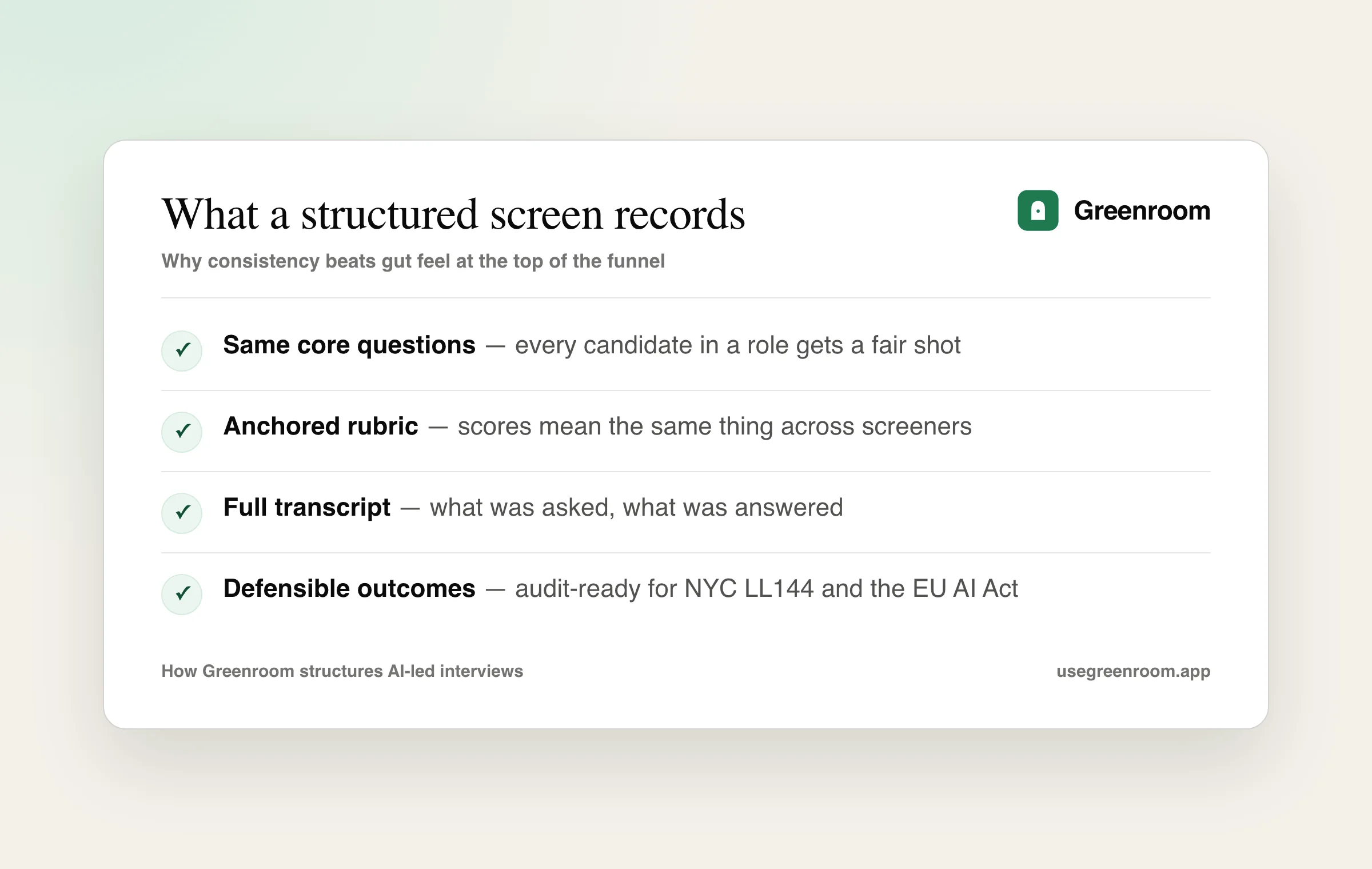
A high-signal phone screen has three properties: the same core questions for every candidate in a role, an anchored rubric so scores mean the same thing across screeners, and a durable record of what was asked and how it was judged. That structure is what lets you compare candidates fairly — and what lets you trust a "pass" enough to stop re-verifying it later.
This is the case for structured AI interviews: not to remove human judgment, but to make the first filter consistent enough that the rest of the loop can rely on it. When the screen is structured, every later stage becomes cleaner, faster, and easier to calibrate — and the software line item pays for itself many times over against that $4,200.
Why structure pays off
Even modest improvements to top-of-funnel consistency save far more than they cost, because the savings compound through every subsequent stage. Fewer false positives means fewer wasted onsites. A shared rubric means faster, less contentious debriefs. A recorded screen means you can audit and improve the questions over time instead of relitigating gut calls. For teams under fairness and documentation obligations, that record matters twice over — see how Greenroom handles NYC Local Law 144 audit artifacts.
The mindset shift is simple: the phone screen isn't a formality before the "real" interviews. It's the highest-leverage filter you own, and the only one whose errors get more expensive at every stage after it. Treat it like the load-bearing decision it is.
Frequently asked questions
How much does a bad phone screen actually cost?
Roughly $4,200 per role for a typical engineering org, once you add wasted onsite interviewer hours, recruiter rework, slower-moving strong candidates and the amortized tail risk of a mis-hire the screen should have caught.
Why are phone screens so inconsistent?
Because they're unstructured by default: different screeners ask different questions, weight answers differently, and write verdicts from memory later. Without a shared rubric, two "strong yes" verdicts can mean completely different things.
What makes a phone screen high-signal?
Three properties: the same core questions for every candidate in the role, an anchored rubric so scores are comparable across screeners, and a durable record of what was asked and how it was judged.
How does Greenroom improve top-of-funnel screening?
Greenroom runs structured AI-led voice screens: every candidate gets the same calibrated questions, answers are scored against an anchored rubric, and the full transcript and scores are recorded — so later stages can trust a pass.