
Somewhere in a Bangalore co-working space, a candidate is explaining their "AI-powered" side project to an interviewer. "So I used LangChain to orchestrate the whole pipeline," they say, with the easy confidence of someone who's said this sentence forty times. The interviewer nods, then asks the question that ends careers built on tutorial-following: "Cool — why LangChain instead of just calling the OpenAI SDK directly for this?" Silence. The candidate's project has exactly one chain, no memory, no agent, no retriever doing anything an if statement couldn't — they imported a framework because the YouTube tutorial did, not because the problem needed one.
This is the actual shape of most LangChain interviews in 2026: less "do you know the API," more "do you understand what problem this framework solves, and can you tell when it's the wrong tool." LangChain itself has matured — it's no longer the default for every LLM project the way it was in 2023, and a chunk of this guide is about that shift. This guide covers the LangChain interview questions that actually come up — chains, agents, memory, retrievers, LangGraph, and the honest "when should you not use LangChain at all" question — organized by topic, with a real answer and working code for each.
What a LangChain interview actually tests
Is LangChain still the default choice for LLM apps in 2026, or has that changed?
It's changed, and a good candidate says so unprompted. By 2026, many teams ship LLM features with nothing more than the provider's own SDK (OpenAI's, Anthropic's) plus their own thin orchestration code, specifically because LangChain's abstractions add a learning curve and a debugging layer that a simple, single-call use case doesn't need. LangChain (and its graph-based sibling LangGraph) earns its place when you genuinely need its value-adds: a unified interface across multiple model providers, a large ecosystem of pre-built integrations (vector stores, document loaders, tools), or — most legitimately — multi-step agent orchestration with state, where hand-rolling the control flow yourself would mean re-implementing a chunk of what LangGraph already solved. The interview-ready framing, and the one that signals real experience rather than tutorial-following: "I'd reach for raw SDK calls for a simple single-purpose feature, and LangChain/LangGraph once I have multiple steps, multiple tools, or need to swap model providers without rewriting orchestration logic."
What's the difference between a LangChain interview and a general AI/prompt engineering interview?
A general AI engineer interview (see our AI engineer interview guide) tests broader system architecture — RAG design, model selection, evaluation — independent of any specific framework. A LangChain-specific interview narrows in on whether you actually know the library's primitives (chains, runnables, agents, memory, retrievers) well enough to read and modify real LangChain code, debug a chain that's behaving unexpectedly, and make an informed call about when LangChain's abstraction is worth its overhead versus writing the orchestration by hand. If a JD specifically lists LangChain or LangGraph, expect actual code — reading a chain definition and explaining what it does, or extending one — not just conceptual questions.
What should I actually have built before this interview?
At minimum, something with more than one step: a simple RAG pipeline (load documents, embed them, retrieve, generate an answer) or a small agent with at least one real tool call. Interviewers can tell within two questions whether you've only followed a single quick-start tutorial versus actually debugged a chain that returned something wrong, dealt with a retriever pulling irrelevant chunks, or hit a LangChain version upgrade that silently changed an import path. If you haven't built anything yet, a weekend RAG project over your own notes or a small document set gives you real debugging stories to draw on — interviewers consistently rate "I hit this specific bug and here's how I found it" far higher than a clean recitation of how the pipeline is supposed to work.
Core chains and runnables questions
What is a Chain in LangChain, and what problem does the newer Runnable/LCEL interface solve?
A Chain combines an LLM call with other steps — a prompt template, an output parser, sometimes another chain — into a single reusable pipeline, so you don't manually wire prompt-formatting, the API call, and response-parsing together every time. The original chain classes (LLMChain, SequentialChain) worked but were rigid and verbose to compose. LCEL (LangChain Expression Language) and the underlying Runnable interface replaced them with a uniform, composable interface — every step (prompt, model, parser, retriever) implements the same Runnable protocol, so you chain them with the pipe operator and get streaming, batching, and async support for free across the whole pipeline, instead of each chain class needing its own bespoke implementation of those features.
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
prompt = ChatPromptTemplate.from_template("Summarize this in one sentence: {text}")
model = ChatOpenAI(model="gpt-4o-mini", temperature=0)
parser = StrOutputParser()
# LCEL: pipe operator composes Runnables into one chain
chain = prompt | model | parser
chain.invoke({"text": "Long article text goes here..."})What's the difference between .invoke(), .stream(), and .batch() on a Runnable, and when do you use each?
.invoke() runs the chain once and returns the complete result after generation finishes — simplest, but the caller waits for the whole response before seeing anything. .stream() returns an iterator that yields output chunks as they're generated, letting you render a response token-by-token in a UI instead of showing a blank screen until the full answer is ready — the right default for any user-facing chat interface. .batch() runs the same chain across a list of inputs, with LangChain handling concurrency for you, which matters for throughput when processing many independent inputs (classifying a thousand support tickets) rather than serving one interactive user. The interview-ready nuance: these aren't just convenience methods, they map directly onto real product decisions — .stream() for chat UX, .batch() for bulk offline processing, .invoke() for a backend call where the caller genuinely needs the complete result before doing anything else (like parsing structured output).
How do you get structured output (a Pydantic model or JSON schema) out of a LangChain pipeline reliably?
The reliable, production answer uses .with_structured_output() on the model, which under the hood uses the provider's actual structured-output / function-calling enforcement rather than just hoping the model's plain-text response happens to parse — the same principle as forcing JSON mode directly against an API, just wrapped in LangChain's interface. Asking for JSON purely through prompt instructions and parsing the raw string yourself works occasionally but breaks the moment the model adds a stray sentence or wraps the output in a markdown fence — exactly the failure mode covered in more depth in our prompt engineering interview guide.
from pydantic import BaseModel
class TicketClassification(BaseModel):
category: str
urgency: str
structured_model = model.with_structured_output(TicketClassification)
result = structured_model.invoke("My payment failed twice and I need a refund urgently.")
# result is a validated TicketClassification instance, not a raw string to parse.invoke/.stream/.batch interface, you can reason about any chain you're handed in an interview, even one you've never seen before.Memory and state questions
What is "memory" in LangChain, and why did the original Memory classes get deprecated in favor of LangGraph state?
Memory lets a chain retain context across multiple calls — most commonly conversation history, so a chatbot remembers what the user said three turns ago instead of treating every message as a fresh, context-free request. The original ConversationBufferMemory-style classes worked for simple chat history but didn't generalize well to more complex state — tracking intermediate agent reasoning, tool call results, or multi-user session state required awkward workarounds. LangGraph's state model replaced this with an explicit, typed state object that flows through a graph of nodes, checkpointed automatically — which handles conversation memory as a special case of the more general problem (any state a multi-step process needs to track and persist), rather than a separate bolted-on concept. The interview-ready answer: for a single simple chatbot, basic message-history memory is still fine and simple; for anything with multiple steps, tool calls, or branching logic, LangGraph's state model is the current, more durable answer.
How would you implement a chatbot that remembers context across a long conversation without blowing the context window?
Pure full-history memory (just appending every message forever) eventually exceeds the context window and gets expensive per call, so production systems use one or a combination of: a sliding window (keep only the last N messages, drop the oldest), summarization memory (periodically condense older messages into a running summary, keeping recent messages verbatim and older context compressed), or retrieval-based memory (store all history in a vector store and retrieve only the most relevant past messages for the current turn, rather than all of them). The interview-ready tradeoff: sliding windows are simplest but can lose important context from early in a long conversation; summarization preserves gist but loses exact wording, which matters if a user references something specific they said earlier; retrieval-based memory scales best for very long conversations but adds retrieval latency and the same "what if retrieval misses the relevant turn" risk that applies to RAG generally.
Retrievers and RAG questions
How does a Retriever fit into a LangChain RAG pipeline, and what's the actual interface?
A Retriever is a Runnable that takes a query string and returns a list of relevant documents — typically backed by a vector store doing similarity search over embeddings, though LangChain's retriever interface is deliberately abstract enough to also wrap keyword search, a SQL query, or a hybrid of several retrieval methods behind the same .invoke(query) shape. This abstraction is one of LangChain's genuine value-adds: you can swap the underlying vector store (Pinecone, Chroma, pgvector, Weaviate) without rewriting the rest of the RAG chain, because everything downstream just calls the same retriever interface.
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
vectorstore = Chroma.from_documents(documents, OpenAIEmbeddings())
retriever = vectorstore.as_retriever(search_kwargs={"k": 4})
retrieved_docs = retriever.invoke("What's our refund policy for annual plans?")What is a multi-query retriever or a re-ranker, and when do you add one?
A multi-query retriever generates several rephrased versions of the user's original query (via an LLM call) and retrieves for each variant, then merges the results — useful when a single phrasing of the query might miss documents that use different wording for the same concept, a real limitation of embedding similarity search. A re-ranker takes the retriever's initial candidate set (often over-fetched, like the top 20) and re-scores them with a more accurate (and more expensive) model before keeping only the best few — useful because cheap vector similarity search is fast but imprecise, while a re-ranking model is slower but much better at judging true relevance. You add either when your eval set shows retrieval quality, not generation quality, is the actual bottleneck — the common interview trap is reaching for a fancier generation prompt to fix what's really a retrieval problem, when the model is doing fine with whatever context it was actually given; the fix was upstream.
How do you evaluate whether a RAG pipeline built with LangChain is actually working well?
The same way you'd evaluate any RAG pipeline, framework aside: a held-out eval set of realistic questions with known-good answers or known-relevant source documents, scored on both retrieval quality (did the right documents come back at all — measurable with precision/recall against labeled relevant documents) and generation quality (given the retrieved context, was the final answer correct and properly grounded — often scored with an LLM-as-judge, with the same caveats about judge bias covered in the prompt engineering guide above). LangChain's own tooling (LangSmith) adds tracing across the whole chain, which helps you see where in the pipeline a bad answer originated — was it bad retrieval, or good retrieval with a generation prompt that ignored the context — but the evaluation discipline itself isn't framework-specific.
How do document loaders and text splitters fit into a LangChain RAG pipeline, and why does chunk size actually matter?
Document loaders handle pulling raw content from a source (a PDF, a webpage, a database, a Notion export) into a standard Document object LangChain's other components can work with. Text splitters then break long documents into smaller chunks before embedding, because embedding an entire long document as one vector loses the specificity needed for precise retrieval — a 50-page PDF embedded as one vector can only ever be retrieved as a whole, even if the user's question is about one paragraph on page 12. Chunk size is a real tuning knob, not an afterthought: chunks too small lose surrounding context that the model needs to answer well (a sentence ripped from its paragraph), while chunks too large dilute the embedding's specificity and waste context-window budget on irrelevant surrounding text. The interview-ready answer: there's no universally correct chunk size — it depends on the document type and query pattern, which is exactly why this is one of the first things worth tuning against an eval set rather than guessing a number once and moving on. Overlap between consecutive chunks (commonly 10-20% of chunk size) is the standard mitigation for the "split right in the middle of an important sentence" problem.
from langchain_text_splitters import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=800,
chunk_overlap=120,
)
chunks = splitter.split_documents(raw_documents)What are LangChain callbacks, and how do you use them to debug a chain in production?
Callbacks are hooks that fire at specific points in a chain or agent's execution — when a chain starts, when an LLM call completes, when a tool is invoked, when an error occurs — letting you attach logging, tracing, or custom monitoring without modifying the chain's own logic. In practice, most teams use LangSmith (LangChain's own tracing platform) rather than hand-rolling callback handlers, since it gives you a visual trace of every step in a chain or agent run — every prompt sent, every model response, every tool call and its result — which is exactly what you need to answer "where in this five-step pipeline did the bad answer actually originate?" The interview signal: candidates who've only ever run chains locally with print() statements haven't hit the actual production debugging problem — a chain failing in a way that's hard to reproduce locally — that tracing exists to solve.
Agents and LangGraph questions
What's a LangChain agent, and how is it different from just chaining steps in a fixed order?
A fixed chain runs the same sequence of steps every time, regardless of input — prompt, then model, then parser, always in that order. An agent instead lets the model itself decide, at runtime, which tool to call next (if any) and when to stop, based on what it's observed so far — the ReAct loop (reason, act, observe, repeat) implemented as actual orchestration code rather than just a prompting technique. The practical distinction matters for debugging: a fixed chain's behavior is fully predictable from its code, while an agent's path through its available tools varies by input and can't be fully predicted in advance, which is exactly why agents need step limits, tool-call logging, and a hard fallback exit far more than a fixed chain does.
Why did LangChain build LangGraph, and what does it add that the original AgentExecutor didn't have?
The original AgentExecutor ran the ReAct loop but treated it as mostly a black box — limited visibility into intermediate state, awkward to add custom control flow like "always run a validation step after this specific tool call," and difficult to persist and resume a long-running agent's state. LangGraph models the whole thing explicitly as a graph: nodes are steps (a model call, a tool call, a custom function), edges define the possible transitions between them (including conditional edges that route based on the current state), and a typed state object flows through and gets checkpointed at each step — which makes complex control flow (branching, loops, human-in-the-loop approval steps, resuming after a crash) something you actually design and see, rather than something the framework decides for you behind an opaque AgentExecutor.run() call. The interview-ready summary: LangGraph trades a little more upfront structure for far better visibility and control over multi-step, stateful agent behavior — worth it once an agent's logic is complex enough that you need that visibility, overkill for a single tool-calling loop with one or two tools.
from langgraph.graph import StateGraph, END
def call_model(state):
response = model.invoke(state["messages"])
return {"messages": state["messages"] + [response]}
def should_continue(state):
last = state["messages"][-1]
return "tools" if last.tool_calls else END
graph = StateGraph(dict)
graph.add_node("agent", call_model)
graph.add_node("tools", tool_node)
graph.add_conditional_edges("agent", should_continue, {"tools": "tools", END: END})
graph.add_edge("tools", "agent")
graph.set_entry_point("agent")
app = graph.compile()What goes wrong with agents in production, and how do you guard against it?
The most common failure is an agent looping on the same tool call repeatedly because the observation didn't resolve whatever uncertainty triggered the call in the first place — without a hard step limit, this either burns API budget indefinitely or hits a provider timeout with no useful result delivered. The fix, standard across LangGraph and hand-rolled agent loops alike: a maximum iteration count after which the agent is forced to either return its best partial answer or explicitly report it couldn't complete the task, plus tool-level guardrails (a tool that modifies real data should require a separate confirmation step, not just trust the agent's judgment that calling it was the right move) — the same production discipline covered in more depth in the guardrails section of our prompt engineering guide.
How do you define and bind a tool in LangChain, and what's the model actually doing when it "calls" one?
A tool is defined as a function with a clear docstring/description and typed arguments — LangChain's @tool decorator (or a Pydantic-schema-based definition) turns it into a schema the model can reason over. "Binding" tools to a model means the model's API call now includes those tool schemas, and the model itself decides, based on the user's input, whether to respond directly or emit a structured tool-call request instead — the model never actually executes the function; your code reads the model's tool-call output, runs the real Python/JS function, and feeds the result back as an observation for the next step. The detail interviewers want unprompted: the quality of the tool's description directly affects whether the model calls it correctly, at the right time — a vague description gets misused or ignored just as often as a vague instruction in a plain prompt, which is the same lesson from prompt engineering applied to tool schemas specifically.
from langchain_core.tools import tool
@tool
def get_order_status(order_id: str) -> str:
"""Look up the current shipping status for a given order ID.
Returns one of: Pending, Shipped, Delivered, or Not Found."""
return lookup_order(order_id)
model_with_tools = model.bind_tools([get_order_status])
response = model_with_tools.invoke("Where's my order A1234?")
# response.tool_calls contains the structured call your code then executes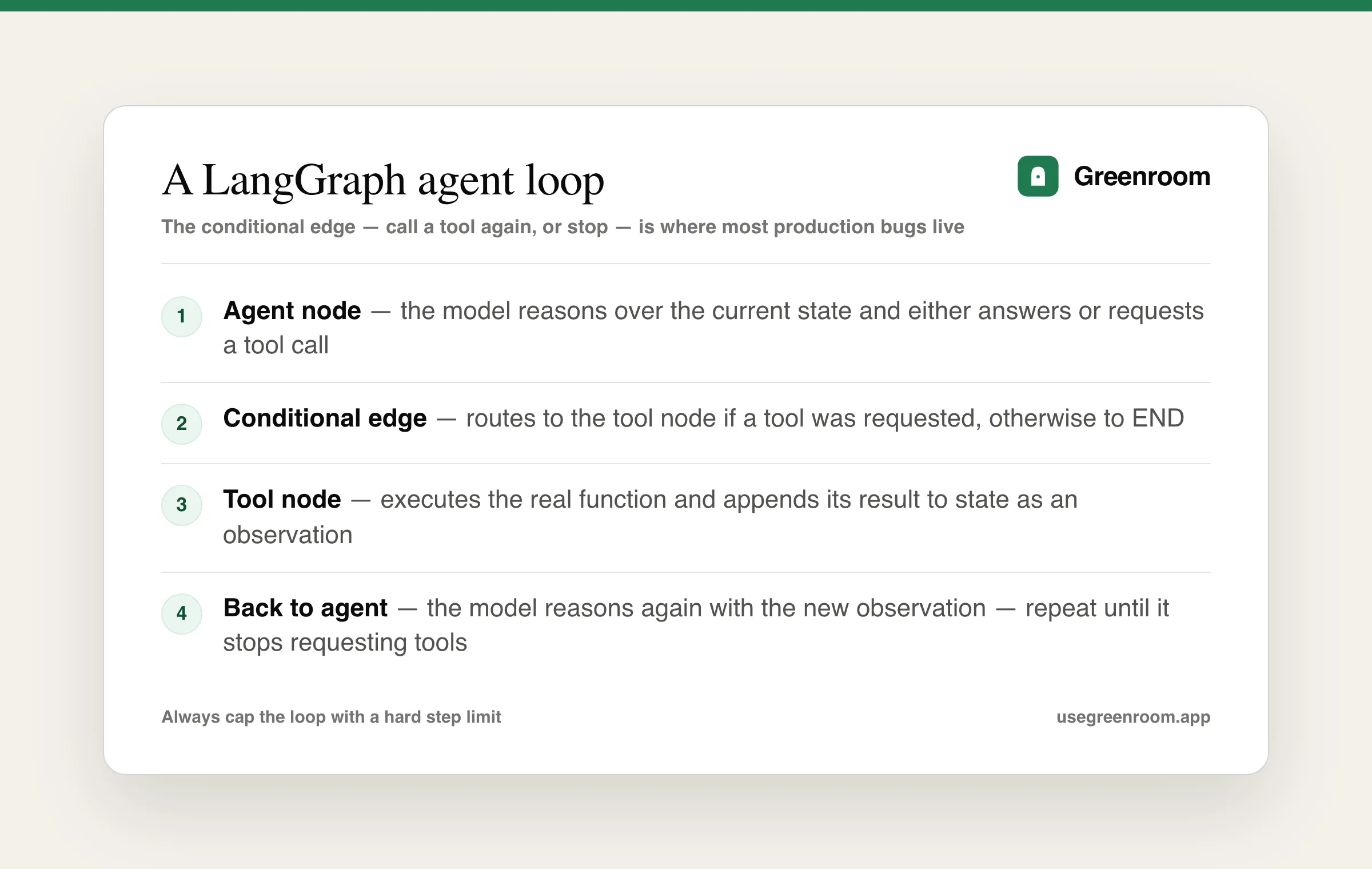
When NOT to use LangChain — the question that separates real experience from tutorial-following
When is LangChain genuinely the wrong choice for a project?
For a single-purpose feature — one prompt, one model call, maybe one parsing step — calling the provider's SDK directly is simpler, has fewer dependencies to keep updated, and is easier for a new engineer to read without first learning LangChain's abstractions. LangChain's version-to-version API churn has been a real, well-known pain point historically (import paths and class names have moved between major versions more than once), which is itself a maintenance cost for a codebase that doesn't need the framework's actual value-adds. The strongest interview answer doesn't trash the framework — it's precise about the tradeoff: "I'd reach for it once I have multiple swappable models or vector stores, multi-step agent logic, or I'm using several of its pre-built integrations — for a single API call wrapped in a prompt template, the SDK alone is simpler and has fewer moving parts to debug."
What's the honest tradeoff of LangChain's abstraction layer?
The upside is real: a unified interface across model providers means swapping from OpenAI to Anthropic to a local model is often a one-line change instead of a rewrite, and the ecosystem of pre-built loaders, retrievers, and tool integrations saves real implementation time for common cases. The downside is also real: an extra abstraction layer between your code and the underlying API call makes debugging slightly harder when something goes wrong — you're now debugging through LangChain's wrapper, not just the API call itself — and the framework's pace of change has meant some codebases accumulate deprecated import paths and patterns across upgrades. Naming both sides unprompted, rather than treating the framework as either obviously right or obviously bloated, is the answer that signals real production experience.
How candidates actually practice this — and where it falls short
Most candidates prepare for LangChain interviews by following the official quick-start docs once, building the canonical "chat with your PDF" RAG demo, and calling it done. That gets you exposure to the happy path — clean documents, a query that retrieves obviously relevant chunks, a model that answers correctly — and almost no exposure to the actual debugging skill interviewers are checking for: what happens when retrieval pulls the wrong chunks, when an agent loops, when a chain upgrade silently breaks an import.
LangChain's own documentation and the official LangGraph tutorials are genuinely the best source for API accuracy, and they've improved significantly since the framework's early, sprawling docs era — naming them shows you've gone to the primary source. They're much weaker on the verbal-interview skill of explaining why you'd structure a chain one way over another when someone is actively pushing back on your choice.
A generic "LangChain interview questions" listicle or a friend's notes gets you the question list without the live-coding pressure or the specific follow-up an interviewer asks when your first answer is too generic — "okay, but how would you actually debug that in production?" — which is where most of the real signal in these interviews lives.
Cloning someone else's GitHub RAG project and reading through it is a reasonable way to see a more realistic, messier chain than a quick-start tutorial — but reading code you didn't write and debug yourself is a different, shallower kind of understanding than being able to explain your own design decisions and the specific bugs you hit building it.
Greenroom runs spoken mock interviews for AI and LLM-framework roles, including live "explain this chain" and "what would you change about this RAG pipeline" exercises with realistic follow-up pushback, and grades the clarity of your explanation, not just whether you used the right vocabulary. Pair it with talking about your GitHub projects if your LangChain project is the centerpiece of your portfolio, since interviewers will dig into exactly the implementation choices this guide covers.
Practise explaining your chain, not just building it
You can follow every official tutorial and still go blank when an interviewer hands you an unfamiliar chain definition and asks "what does this do, and what would break it?" That specific skill — reading orchestration code you didn't write, reasoning about its failure modes out loud, and defending your own design choices under follow-up pressure — is what separates candidates who've built one demo from candidates who've actually debugged something in production. Greenroom runs spoken mock interviews for AI engineering roles with live chain-reading and agent-design exercises, and feedback on how clearly you explain your reasoning. Pair it with our AI engineer interview questions guide for the broader system-design side, and prompt engineering interview questions for the prompting layer underneath every chain.
Frequently asked questions
What should I study for a LangChain interview?
Start with the Runnable/LCEL interface (.invoke, .stream, .batch, the pipe operator for composing chains), structured output, memory and state (including why LangGraph replaced the original Memory classes), retrievers and RAG evaluation, agents and the ReAct loop, and LangGraph's graph-based state model for multi-step orchestration. Just as important: be ready to explain when you would not use LangChain at all for a given problem.
Is LangChain still worth learning in 2026, or should I just use provider SDKs directly?
Both, depending on the problem — and a good interview answer says so. Provider SDKs are simpler and sufficient for single-purpose features with one model call. LangChain (and LangGraph specifically) earns its place once you need multi-step agent orchestration with state, swappable model providers, or its ecosystem of pre-built retriever and tool integrations. Most production teams in 2026 use a mix: simple SDK calls for simple features, LangGraph for genuinely complex agent logic.
What's the difference between LangChain and LangGraph?
LangChain provides the building blocks — chains, prompts, retrievers, the Runnable/LCEL interface, integrations with model providers and vector stores. LangGraph is built on top of LangChain's primitives specifically for stateful, multi-step agent orchestration, modeling control flow as an explicit graph of nodes and edges with a typed, checkpointed state object — replacing the older, less visible AgentExecutor approach for complex agent logic.
Do LangChain interviews require live coding?
Often yes, more so than a purely conceptual AI interview — expect to read a chain definition and explain what it does, extend an existing chain with a new step, or debug a snippet that's behaving unexpectedly. Conceptual questions (memory vs. state, when to use an agent vs. a fixed chain) usually come first, with live code as a follow-up to verify you can actually work with the library, not just describe it.
What's the biggest red flag candidates show in LangChain interviews?
Having only ever followed a single quick-start tutorial, with no real debugging story — when asked "what went wrong building this, and how did you fix it," candidates with only tutorial experience have nothing concrete to say. The second red flag is reflexively defending LangChain as the right choice for everything, rather than being able to name when a raw API call would have been simpler.
How do I get real LangChain debugging experience before an interview if I don't have production experience?
Build something with an intentionally messier, more realistic edge case than a tutorial covers — a RAG pipeline over documents with inconsistent formatting, an agent with a tool that sometimes fails, a retriever that needs re-ranking because plain similarity search returns irrelevant chunks. Hitting and fixing a real bug in your own project, even a small one, gives you a concrete debugging story that's far more convincing in an interview than reciting how the framework is supposed to work in the ideal case.